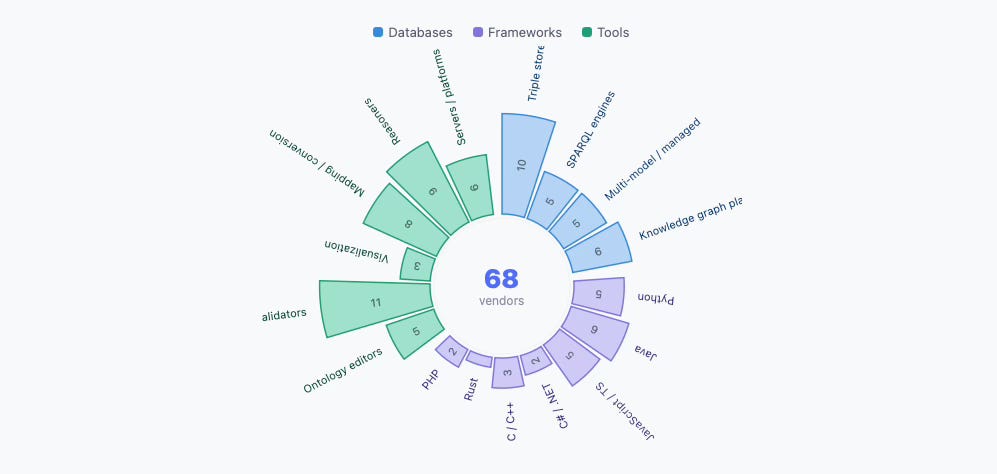
68 vendors, one data model
An overview over the knowledge graph landscape.

When people hear “knowledge graph”, they might think of some LPG (tm) or maybe have a faint memory of Google’s Knowledge Graph announcement from 2012. What most don’t realise, I think, is that there is an entire ecosystem of databases, frameworks, and tools built on open standards from W3C that has been powering some of the most demanding data integration challenges there is.
That’s standard RDF! And after spending over a decade of my career as a consultant, advising on vendors and tooling, and some time on research, I can tell you: the ecosystem is far bigger, more mature, and more alive than you might think!
Why bother building this
I’ve been a knowledge graph practitioner for over a decade. Most of my time as a consultant (Acando and Capgemini), but since September last year in a product development company (Data Treehouse). During my career I’ve had to pick and choose the right tool for the job, and I’ve often met sceptics and people believing there are no mature market. (2005 called and wanted their assumptions back!) As far to my knowledge, there are no comprehensive list of this (other than Awesome Semantic Web on GitHub, ofc), so I wanted to build an up-to-date list with comparison functionalities, filters and a note on what the “big guns” are doing in this area. And I find it so delightful that with knowledge and ideas, you can create informative presentations with a bit of vibe-coding. My research assistant and UX-designer of this site is Claude Opus 4.6.
The result became 68 vendors described: 19 databases, 23 frameworks in 7 programming languages, and 26 tools ranging from ontology editors to SHACL validators to visual graph explorers.
Food for thought
The ecosystem is truly international. Vendors span 16 countries across four continents. Norway, Netherlands, Germany, Bulgaria, UK, US. RDF tooling isn’t dominated by a single region the way some technology ecosystems are. Academic origins in Europe have translated into a strong commercial presence, but there is significant activity everywhere.
The language coverage is deep
There are mature, actively maintained RDF libraries for Python, Java, JavaScript/TypeScript, C#/.NET, C/C++, Rust, and PHP. Whatever stack you’re building on, there’s likely a well-supported RDF library for it.
Performance is king
The old criticism that RDF databases are slow compared to property graphs does not hold anymore. Several triple stores now handle billion of triples with sub-second query times. The latest generation of Rust-based tools (Oxigraph, maplib) brings near-native performance to RDF processing. And the benchmark numbers are public, you can verify the claims yourself.
The big platforms are mostly hanging behind
I audited what Microsoft, Google, SAP, Amazon, Databricks, Snowflakse, and others offer for RDF. And I am not surprised that only Oracle, SAP, and AWS have first-party RDF/SPARQL support. Others puts makeup on the pig. Or have invented their own monstrous mutant pig. Google, Databricks, Snowlake, Elastic—none of them support W3C semantic standards natively. Microsoft’s new Fabric IQ is the most interesting recent development, which has an ontology layer that can import and export RDF/XML1, but queries use GQL and KQL, not SPARQL. It’s RDF-adjacent and not RDF-native.
Interoperability in 1-2-3!
The RDF ecosystem is fundamentally different from property graphs world, because your data is portable!
A knowledge graph built in maplib can be queried in GraphDB, validated with pySHACL, visualised in WebVOWL, and served through Fuseki. (Another question is if you really wanna do that. maplib has the fastest SHACL engine in the world, up to 159x-times faster than GraphDB on SPARQL and contain a built-in graph visualiser.) You can seamlessly port RDF data from vendor to vendor without a single format conversion or migration script. That’s the consequence of implementing the same, open W3C standards.
That you cannot do between property graphs, as there’s no shared data model underneath.
RDF gives you something that’s a bit rare in enterprise software, which is zero vendor lock-in! Not “we have an export button” lock-in avoidance, but “your triples work identically across 19 different databases” interoperability. You own your knowledge graph, and the vendor is just the runtime.
The things that are on the map
The landscape is organised into three tiers.
Databases
These range from established enterprise triple stores like GraphDB and Stardom to managed cloud services as Amazon Neptune, to lightweight embeddable stores like Oxigraph. The sub-categories showes the diversity of dedicated triple stores, SPARQL engines, multi-model databases, knowledge graph platforms, and virtual knowledge graph systems that query your existing relational databases through a SPARQL lens without moving any data.
Frameworks
Frameworks cover most major programming language. Apache Jena dominates Java, and there’s active competition in JavaScript (rdflib.js, N3.js, Communica). The Rust ecosystem is young, but fast! maplib represent a new generation of high-performance RDF tooling.
Tools
This category includes editors, validators, mapping tools, reasoners, and visualisation platforms.
Every vendor in the landscape is tagged with supported W3C standards, focus areas, performance characteristics, region of origin, and licensing model. You can filter, compare, and use a guided lizard to find the right tool for your specific use case.
Query the underlying data
The underlying data for this vendor landscape is RDF. Feel free to fool around with the data, query it and extend it.
Every vendor, focus area, standard, and region is an IRI. The build step uses maplib run SPARQL queries on it and generate JavaScript that powers the website. An RDF vendor landscape, powered by RDF.
The site, data and the build tooling are all open source. If you spot an error, or want to add a vendor, the repo is on GitHub and feel free to add issues.
Sup next?
The landscape is a snapshot, not a finished product. It’s built together with Claude, and I find it funny how all my ideas are just a few keystrokes away.
RDF tooling is evolving fast, and RDF 1.2 and SPARQL 1.2 is just around the corner. And I’ll try to keep this updated as well as I can.
If you work with knowledge graphs, semantic web technologies, or just data integration at scale, I’d encourage you to explore the full landscape. The RDF ecosystem deserves to be better known. And if you’ve been building on property graphs and wondering about interoperability, standards compliance or semantics—this might be with a closer look.
About the author
Ontologist who code in C, Java and Python. Been a knowledge graph practitioner for over a decade, and had numerous talks on the topic around the globe. Knowledge Graph Specialist at Data Treehouse. Author of SHACL for the Practitioner and awarded amongst Norway’s Top 50 Women in Tech 2024.
XML!! In 2026!!
Appreciated Veronika. Virtuoso - 1998 - omg
Love how the same unlocks bringing the onslaught of attention to things so many people think are groundbreaking new…can be used by the true industry experts and practitioners (like Veronika) to spin up mechanisms to get their voice, tools, and research out into the open with minimal effort. Love it. We need this. Thank you.
Great stuff … is there a master list of vendors you have created as a reference ?